I find Perl to be a great language to use for both small-scale one-liner type tasks and as well a for large-scale multi-file applications. However, I need reminders of its usage details every now and again. While I could read the relevant manpages via perldoc, they are somewhat dry and technical (they are manpages after all!). I found these recent tutorials/references much more easier reading.
Moose is the Object Oriented foundation for Modern Perl. I found the following Moose presentation by the eminent Perl hacker RJBS very informative. It seems to nicely describe all the latest functionality of Moose (as of August 2010).
Imagine that you are the Chief Chocolate Inspector of a chocolate factory. Your job is to ensure that the days production of chocolate by the factory is of good quality. Only upon your recommendation will the factory be shipping out its days worth of chocolate production to its distribution points.
The chocolate factory consists of three adjacent rooms connected together by a conveyor belt/assembly line.
The first room is where the chocolate pieces are produced and initially placed onto the conveyor belt. The factory produces a variety of decadent chocolate types simultaneously and randomly places each type onto the conveyor belt.
The second adjoining room is where each of the individual chocolate pieces get wrapped up. Afterwards, you are given a choice whether to choose that particular piece for taste inspection, or ignore it and wait for the next one.
The final adjoining room is where the chocolate pieces get packaged together in boxes and loaded onto the delivery trucks. The trucks only move upon your decision at the end of the day.
Your goal, as the Chief Inspector, is to notify the truck drivers if the packages are suitable for shipping in as efficient manner as possible. Armed with a special selection bin to hold pieces of chocolate, you decide to choose uniformly random pieces of chocolate out the total pieces of chocolate produced by the factory throughout the day, where . Afterwards, you base your taste decision on this random subset.
Unfortunately, you have no idea as to how many chocolate entities will be passing by on any given day. Some days, the amount of chocolate produced by the factory is very high, on others it is pretty low. In other words, you do not know what is beforehand.
While you could wait to make the sampling after the days production is done; you don’t want to hold up the assembly line making these quality control choices. “I Love Lucy” has shown what kind of hijinks can happen if this process goes awry.
What to do?
One solution to this problem might be to roll a die as each chocolate piece passes you. If the die rolls even, hold the chocolate for inspection in the selection bin. Otherwise, let the chocolate pass through. If the selection bin is full when choosing a chocolate piece, simply replace the oldest chocolate piece in the bin with the new one.
In this naïve approach, one is biased against keeping the earliest chocolate samples with the ones selected later in the day. To resolve this issue, you can use a loaded die or get more “Dungeons & Dragons”-esque by using more sophisticated dice and rules as the day progresses.
Then with some luck, you could get a uniform sampling of the days production of chocolate.
But there is a better way…
A Smarter Way
Suppose you could assign a uniform random (i.i.d of course!) number from to each piece of chocolate you encounter on the assembly line.
Now, to obtain a sampling of the days production of chocolate, simply choose the chocolates corresponding to the lowest random numbers linked with them. Each chocolate piece has an equal chance of being in the lowest choices, so the sampling is uniform.
With the ubiquitous computing power available these days, you could substitute using dice with a iPhone or Android app to help out. Each time you see a new chocolate piece, generate a random number with your app. Hold onto the chocolate pieces that correspond to the lowest random numbers. If you encounter a new chocolate piece that is linked with a random number that is lower than the largest random number associated chocolate already in your selection bin, simply replace the old one with the new one.
By the end of the process you now have uniform samples of the entire days chocolate production, and you never needed to hold onto more than those items. Pretty clever, eh!
This approach could be optimized even further. For example, you could preemptively generate a large list of random numbers; identify the lowest ones; and afterwards directly choose those chocolate pieces as they appear off the production line and bypass the rest.
Amazingly, you could sample the entire days production of chocolates, , in less than time. According to this fellow, you can make the process efficient.
These techniques of sampling a set of unknown size through one pass are called reservoir algorithms.
The “Real” World
While most of us are not chocolate inspectors, we are all nowadays swamped in a “sea of data”, from science and business to personal tracking. Often times these raw data sets come in large chunks. One data-mining technique to get a better handle of the data is sampling it. Sometimes less is more. Now chocolate pieces become record sets and the assembly line becomes a large file.
The basic premise of genetic sequencing involves preparing a DNA sample into a form suitable for use on a DNA sequencer. Afterwards, the sequencer ascertains the sequences of bases on the preapred sample and stores these results into a digital file. These file formats are related to the sequencing methodology taken by the sequencer.
Most scientists/biologists are more interested in the final sequence data produced rather than the particular vendor technology itself.
During the course of the biological investigation, one often is confronted with data from various sequencing platforms. A format is needed that is common across platforms. In the era of next-generation sequencing, it appears that the Sanger FASTQ format is the popular lingua franca of sequence file formats. It holds both the sequence and quality data generated by the sequencer. Many of the currently popular (and open-source) aligner and assemblers such as maq, bwa, bowtie, SSAHA2 and velvet accept Sanger FASTQ files as their inputs.
In the world of 454 sequencing, Roche 454 has their own set of tools to work with the data. Unfortunately, they are not freely available. While the 454 tools from Roche provide a way to convert their data into a FASTA file format, another device independent sequence file format; there is not a direct SFF to FASTQ conversion utility.
I have been going through a bit of a mathematical refresher lately. It has been a while in directly dealing with things of a probabilistic and statistical nature. In particular, I was reading up on Bayes’ Theorem and Bayesian inference. Bayes’ rule is a subtle mathematical statement that has deep interpretations and implications. Below were three introductory write ups I found upon the subject, each with a slightly different perspective of presentation.
I am a perpetual apprentice to the oft neglected and under appreciated art of writing well. Words, either written or spoken, are the most powerful means of communication we have. While images, animations, sounds, and music certainly have the ability to capture our attention and engage us, words are needed to persuade, instruct, and argue.
The words you use, either written or spoken, can have powerful effects on your audience‚—if you use them carefully and skillfully. Whether your goal is to inform, to persuade, to call for action, or to entertain, your words and your stories can be powerful. They can be powerful, because language is software for the mind
For the past few years, aside from corporate email speak, I have spent the majority of my time writing software for computers. This has placed my writing, or software for the mind skills, a bit in the backseat. Obviously, being well read, and practice writing are the keys to improvement; however, there are times when direct discussion about the topic itself proves helpful. Below are a few resources that I have found in the past few months that maybe useful.
The Elements of Style — This 92 year old book is always ever popular by writers. Its tips about the fundementals are always worth perusing.
The New York Times: Grammar and Usage Section — There are a plethora of interesting articles and resources about writing here. The prestigious newspaper also critiques itself in the After Deadline section. Even the professionals make mistakes too, and still work to refine their craft.
President Obama giving his Nobel Prize Speech at Oslo City Hall (source whitehouse.gov)
On December 10 2009, President Obama gave his Nobel Prize acceptance speech at the Oslo City Hall. He was the first sitting president to receive the prize since Woodrow Wilson. The speech was interesting in how he juxtaposed the philosophical need for war, in light of recent events in Afghanistan and Iraq, with an acceptance of a peace prize. Clearly, it was an eloquent talk intended to be experienced again after some aging, much like a fine wine. I wonder how this speech will feel when sampled many years in the future.
I recently came across some nifty overviews of topics that are of recent interest in genetics research. The cool thing was, that they were in video form. Being a TV addict, this was all too good to be true.
microRNAs
microRNAs, or (miRNA) are short stranded RNA molecules that are thought to regulate gene expression in the eukaryotic cell. I’m sure things are a bit oversimplified in the following YouTube video, but nevertheless, it gives a high-level overview of what is going on.
Epigenetics
Back in July 2007, NOVA‘s ScienceNOW program with Neil deGrasse Tyson, had an episode dealing with epigenetics. Epigenetics, as stated by wikipedia, refers to changes in phenotype (appearance) or gene expression caused by mechanisms other than changes in the underlying DNA sequence. Unfortunately, I could not find a YouTube-like link of that episode to place directly in the blog post. Please go here to view the show.
Welcome! I decided to migrate from my old blog site to here after noticing all the extra features provided by the more competitive WordPress.com and Blogger. Many of these features were not available (or at least observable) to me at LiveJournal. Also recentnews does not seem to bode well with expecting new upcoming features from LiveJournal. Lets see how the blog evolves from here.

 pieces of chocolate, you decide to choose
pieces of chocolate, you decide to choose 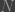 total pieces of chocolate produced by the factory throughout the day, where
total pieces of chocolate produced by the factory throughout the day, where  . Afterwards, you base your taste decision on this random subset.
. Afterwards, you base your taste decision on this random subset.
 to each piece of chocolate you encounter on the assembly line.
to each piece of chocolate you encounter on the assembly line. time.
time.  efficient.
efficient.

